Por qué debes comenzar a pensar en una estrategia de 1st Party Data
Por qué debes comenzar a pensar en una estrategia de 1st Party Data
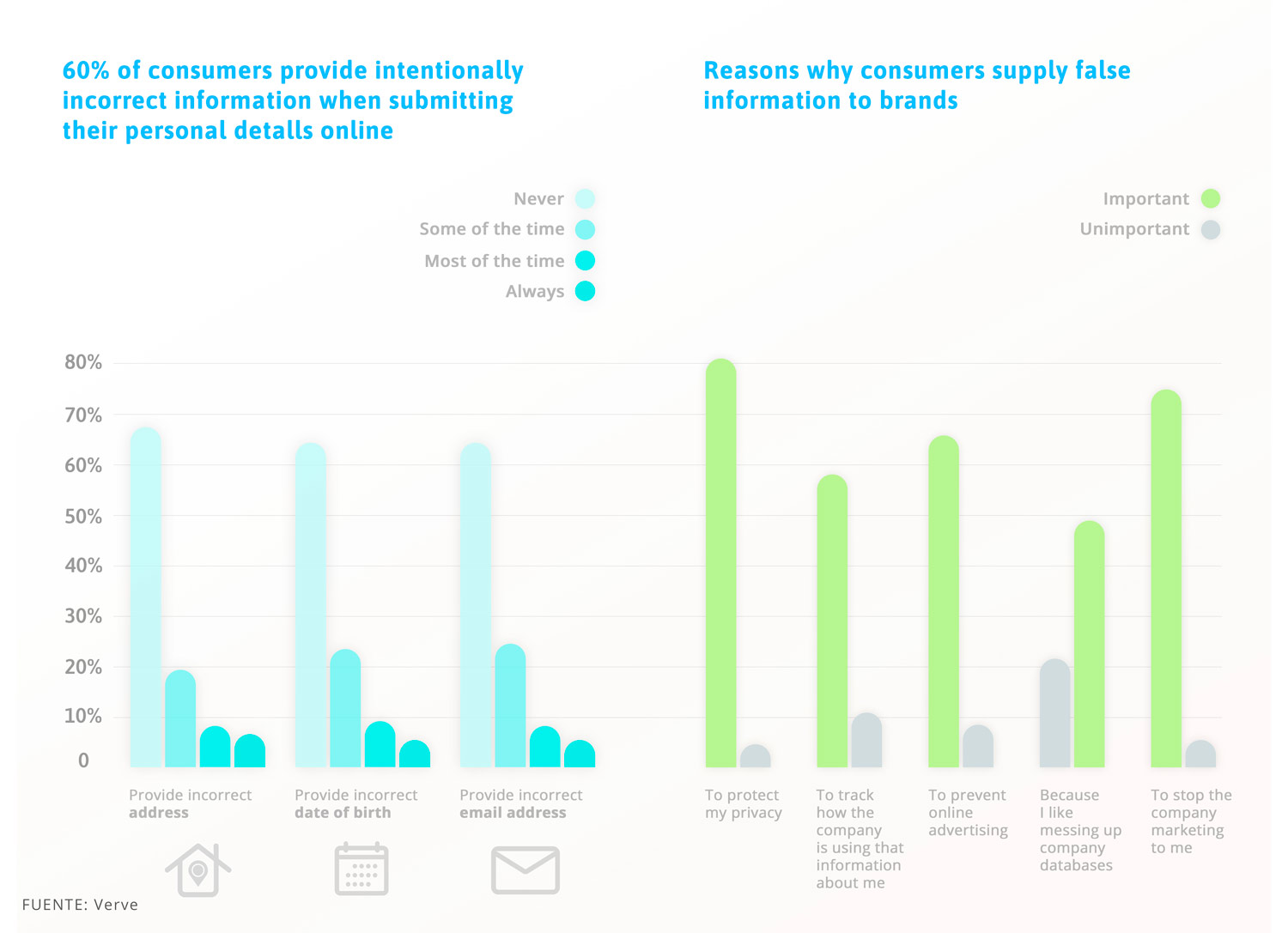
Google anunció que Chrome no admitirá cookies de terceros en dos años. Este hecho hace que, desde ya, sería recomendable empezar a pensar en una estrategia relacionada con los datos propios, que te permita seguir adquiriendo clientes nuevos, aumentar tu reconocimiento de marca y todo de acuerdo con la normativa legal vigente. En este post te voy a hablar de qué es el 1st Party Data, por qué debes empezar a prestar más atención a este, sus ventajas, así como de qué manera recopilarlos, qué datos recopilar y cómo ponerlos en uso. ¿Seguimos? Vamos allá.
Todos sabemos que las cookies de terceros se enfrentan a amenazas existenciales de los navegadores y reguladores de datos. Sin embargo, es probable que en un corto periodo de tiempo, la industria presente una alternativa a las cookies. Además, las asociaciones han comenzado a explorar diferentes métodos, así como el Iab y Google, quienes propusieron nuevos estándares publicitarios desde sus puntos de vista extremos.
No hay duda, que el año 2020 está siendo un año clave para el aumento de la relevancia de los datos propios. Pero ¿qué son exactamente?
Los 1st Party Data o datos de origen, se refieren a cualquier dato que recopile la empresa de sus fuentes propias de datos, como su página web, sus redes sociales, el CRM, su servicio de atención al cliente… Como editor o empresa, recibirás millones o cientos de visitantes a tu site, tendrás miles o decenas de suscriptores a tu boletín de correo electrónico y cientos de comentarios / encuestas. Además, cada evento y vista de página genera varios puntos de datos que puedes utilizar para orientar campañas publicitarias, comprender a tus usuarios, optimizar la experiencia del sitio y mucho más.
Por ejemplo, una vista de una sola página genera 40 puntos de datos. Ahora, imagina cuántos puntos de datos se generarían en un día o en un mes. Muchísimos, ¿verdad?
Los datos son exactamente lo que buscan tanto los anunciantes como las marcas mientras ejecutan sus campañas. Por lo tanto, es importante tener una estrategia eficiente para recopilar, almacenar y utilizar los datos, bien seas un medio online o un eCommerce que busca mejorar la experiencia de usuario, con el fin de convertir a esos potenciales clientes.
Si quieres profundizar en qué son los datos propios, te recomiendo que eches un vistazo a este post sobre “Qué es el 1st Party Data y qué ventajas aporta a tu estrategia de marketing”.
Si prefieres ir al grano, vamos con los motivos de por qué debes empezar a prestar más atención a este tipo de datos.
Por qué debo priorizar los 1st Party Data

Como te he comentado, este año 2020 es un año clave en cuanto a la importancia de este tipo de datos en la transformación digital de las empresas. Y es que tu empresa, si quiere seguir creciendo o comenzar a crecer como te gustaría, debe de alejarse lo máximo posible de los datos de terceros, o al menos no centrarse en ellos.
Los principales motivos de este argumento son estos:
- Se van a producir cambios en los navegadores web, no sólo por parte de Chrome, sino de todos los demás.
- Las Leyes de privacidad de datos ya golpearon fuerte sobre los 3rd Party Data, pero sólo acaba de comenzar. Se estima que cada vez serán más restrictivas.
- La posibilidad de personalizar sin datos de terceros.
Y es que no sólo los motivos son decisivos, sino que, además, el centrar tu estrategia en la recopilación de datos propios, te puede aportar una serie de ventajas. Te las puedo resumir en estas tres:
- Te permite generar ingresos, gracias a la adquisición escalable de clientes.
- Reducción del tiempo en la obtención de conocimiento, a través de los datos.
- Tener un control de los datos, de acuerdo con el consentimiento del cliente.
Pero ojo, que se diga que se debe de priorizar el uso de datos propios, no quiere decir que se sustituyan unos por otros. De lo que se trata, es de poder complementarlos, disponiendo así de datos más ricos y estratégicamente alineados que encajen con los objetivos del negocio.
Disponer de una estrategia de 1st party data, requiere de una estrategia de recopilación y uso de esos datos, que además de ser sólida, sea adaptable.
Recopilación de datos de origen

Esta es la primera fase, y por tanto, es crítica. Si esto lo definimos mal, el resto del proceso será inexacto.
Podemos categorizar este proceso en dos partes:
1 Datos a recopilar.
Antes de comenzar en este aspecto, se debe de tener muy claro el propósito que existe detrás de la recopilación de datos, es decir, por qué recopilamos datos, para así poder concentrarnos en qué datos recopilar.
De todo lo que se puede hacer, quizás un ejemplo muy sencillo es el relacionado con la publicidad. De este modo, nos centraremos en dos temas generales. Así, por ejemplo, el primer propósito podría ser el conocimiento de la audiencia y el segundo la publicidad.
Una vez tenemos claro el propósito, lo siguiente que deberíamos hacer es determinar cuáles serán los puntos de datos. Para los dos propósitos que he mencionado anteriormente, los puntos de datos podrían ser estos:
- Clics en toda la página.
- Cualquier descarga o suscripción al boletín dentro de la web.
- Medios en la página.
- Consultas de búsqueda.
- Comentarios, temas y publicaciones en foros de la empresa.
- Metadatos de la página.
- URL.
Además, puedes acceder a otros puntos de datos como:
- Años.
- Género.
- Ubicación.
- Ingresos del hogar.
- Estado civil y tamaño de la familia.
- Intereses.
- Preferencias.
- Historial de navegación.
- Historial de compras.
- Uso de las RRSS…
Si además, haces encuestas, puedes añadir toda esa información a tu CRM y tener así un perfil bastante completo de cliente.
2 Cómo recopilar.
Quizás la mayor duda que se te plantee está en cómo recopilar esos puntos de datos. Hay múltiples herramientas que pueden ayudarte a hacer muy bien este trabajo, pero quizás es mejor comenzar por las más simples y accesibles a cualquier empresa, como son:
#1. Google Analytics.
La herramienta de Google te permite monitorizar tu tráfico web para comprenderlo y sacar muchos de los puntos de datos que necesitas. Además, puedes conectarlo con Google Ads, sacándole mucha más información y conocimiento.
#2. Hotjar / Smartlook.
Ambas son herramientas de mapas de calor para la web, que pueden ayudarte a reconocer cómo los usuarios interactúan con el contenido de tu site. Puedes rastrear dónde hacen clic, los movimientos del cursor, la profundidad de desplazamiento y muchas cosas más.
#3. Los pixeles de seguimiento.
No es necesario que te cuente mucho sobre ellos, ya que seguro que los utilizas a menudo. Es probable que todas las tecnologías de marketing y plataformas publicitarias que utilizas usen píxeles en sus páginas para colocar cookies, de modo que los datos anónimos del usuario se puedan recopilar para los fines previstos.
Un ejemplo simple pueden ser los píxeles de Facebook. Cuando ejecutas anuncios de Facebook, la plataforma social te pedirá que coloques sus píxeles de seguimiento y conversión para rastrear el tráfico y las conversiones. Del mismo modo, podrás recopilar datos de usuario si utilizas píxeles en las páginas.
#4. DMP.
Por último, pero no menos importante, las plataformas de gestión de datos (DMP). Los DMP están diseñados específicamente para recopilar datos de origen y ponerlos en uso. El objetivo de estos, es generar segmentos para identificar audiencias objetivo más adecuadas a las que dirigirse en cada acción publicitaria, es decir, apuntar mejor en cada campaña al público que realmente te interesa. Surgieron a raíz de la compra programática, ya que ayuda mucho a las agencias, anunciantes y trading desk que la utilizan. Quizás sea la opción más fácil disponible para cualquiera. Si puedes pagar un DMP, te recomiendo que lo pruebes.
#5. CDP.
Quizás menos conocido, pero con un potencial muy alto de aprovechamiento del 1st party data. CDP no es otra cosa que una plataforma de gestión de datos de clientes. En estas plataformas, puedes crear fichas únicas de clientes con todos los datos propios que dispongas. Del mismo modo, puedes enriquecerlos con conexiones seguras a fuentes externas, y automatizar acciones en las plataformas de marketing con las que trabajes, en función de diferentes triggers. Si quieres saber más sobre esta tecnología, te invito a echar un vistazo este post sobre «Qué es un CDP y qué ventajas tiene«.
Pues bien, ya los tenemos recopilados, ahora toca ponerlos en uso.
Puesta en uso de los datos.

Esta es la parte más importante, en la que nos debemos de preguntar ¿cómo podemos aplicar los datos que hemos recopilado para mejorar la experiencia de usuario y los ingresos?
Los 1st party data, son los que definen la experiencia de tus clientes con tu marca, siendo uno de los activos más valiosos de tu empresa. Gracias a ellos, podrás tener una visión real de lo que sienten tus usuarios, pudiendo tomar decisiones al respecto, y crear estrategias que deriven en acciones para la mejora.
Pero existe un problema y es, que a medida que el volumen, la variedad y la velocidad de los datos que la empresa es capaz de recoger, aumenta, muchos equipos de trabajo se ven superados por ellos, colapsándose ante tanta información, no llegando a ponerla en uso. Si a esto le unimos que las empresas afrontan el desafío de recopilar, transformar y poner en uso los datos de clientes cumpliendo al mismo tiempo la normativa nueva y cambiante, nos damos cuenta de que no es tarea fácil.
Por ello, para poder hacer un uso adecuado de esos datos, es necesario disponer de una tecnología que te ayude y una empresa experta con know-how que sepa sacar partido a esos datos.
Por ejemplo, en el caso de buscar una adecuada experiencia de usuario, Google Analytics se suele utilizar para conocer el comportamiento del usuario y a su vez, Google Ad Manager para anuncios. Cuando los vinculas, puedes generar informes que te ayuden a evaluar cómo los anuncios afectan la experiencia del usuario y viceversa.
Ese hecho puede ser mucho más relevante disponiendo del equipo apropiado especializado en dicha analítica, el cual a su vez, sea capaz de sacar más y mejores conclusiones de negocio.
En artyco llevamos muchos años trabajando con los datos propios o 1st party data de empresas líderes como Mercedes-Benz o LG, poniendo a su disposición tanto nuestro talento como la tecnología más adecuada a sus necesidades. ¿Hablamos?







Emilio Fernández Lastra
“Después de la hipoteca, el inbound marketing es la mejor
herramienta para asegurar una relación a largo plazo”
¿Te ha parecido interesante lo que has leído?
En artyco podemos ayudarte a conseguir tus objetivos
¿Hablamos?





© Artyco comunicación y servicios - Todos los derechos reservados
© Artyco comunicación y servicios - Todos los derechos reservados