
Qué es el Dirty Data
Qué es el Dirty Data
Dirty Data o datos sucios, es el término que se utiliza para denominar a aquella información que es errónea, inconsistente o incompleta. Incluso puede ser Dirty Data, todos aquellos datos mal relacionados, con campos vacíos o con información falsa. A priori podrías pensar que este tipo de datos no merecen un post, sin embargo, si te cuento que el impacto del Dirty Data en España se ha cifrado en 321 millones de euros de pérdidas, la cosa cambia, ¿verdad? En este post no sólo te ayudaré a entender mejor lo que son los datos sucios, sino que, además, te contaré cuáles son las principales causas, y su solución posible: el Data Cleaning.
Las plataformas de Big Data no tienen en cuenta el Dirty Data, es decir, funcionan incluso con datos erróneos, incompletos o inconsistentes, ofreciendo información y conclusiones equivocadas, las cuales originan desastrosas tomas de decisiones.
Sin embargo, en realidad, la gravedad depende el volumen de Dirty Data que hubiera en la plataforma. Según algunos estudios, el 82% de los datos almacenados por las organizaciones es Dirty Data. ¿Te parece demasiado? Imagina el daño que puede hacer a las conclusiones que de ellos pueda sacar tu equipo de Customer Intelligence.
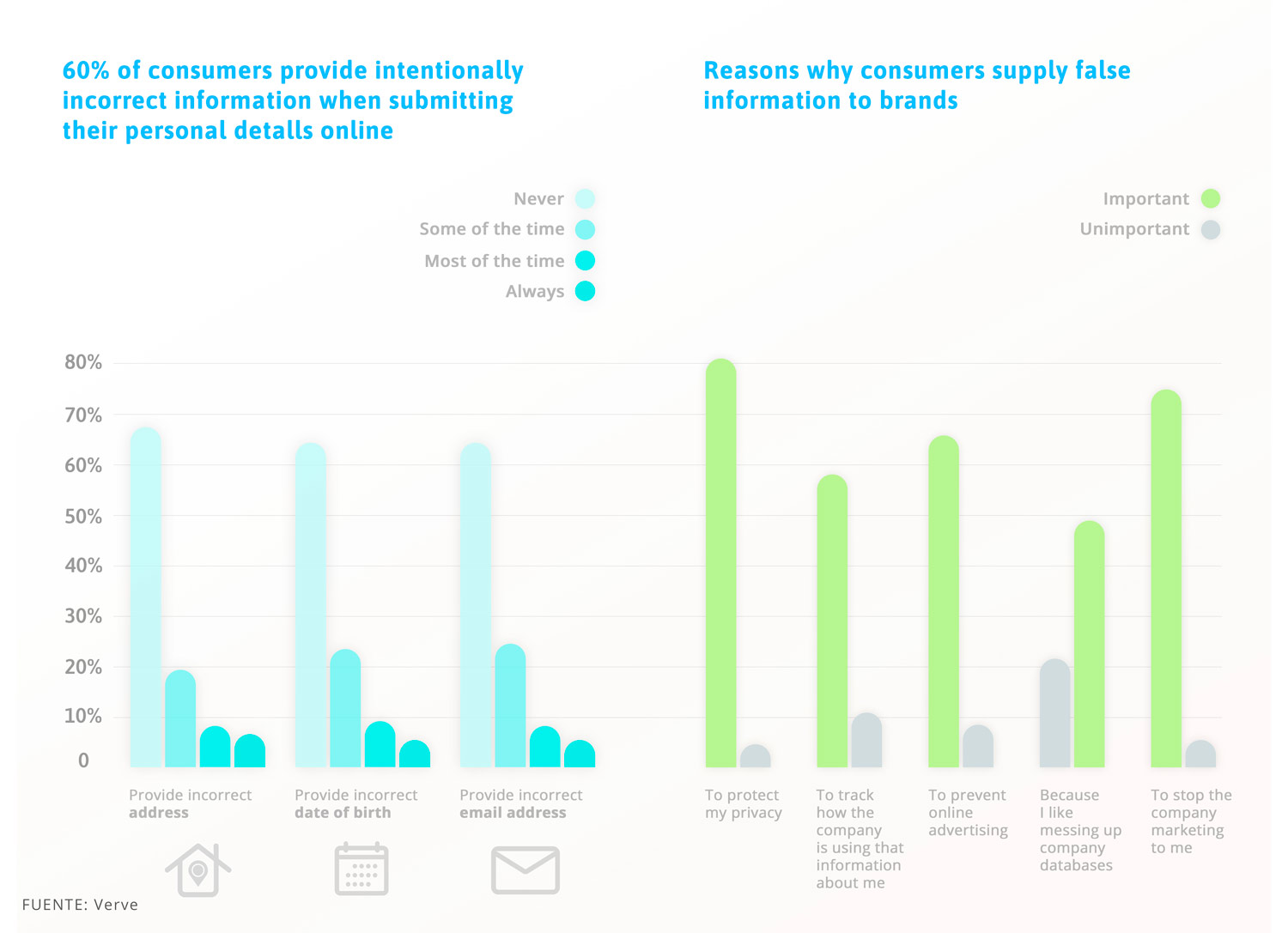
Y es que según la firma Verve, el 60% de los consumidores mienten en algún dato a la hora de rellenar sus datos personales, y según la compañía Hocelot, cerca del 25% de los datos que tiene una compañía, podrían ser falsos.
¿De qué sirve disponer de las mayores fuentes de recogida de datos, así como de las infraestructuras más potentes para almacenarlos y la mejor analítica, si los datos que allí se guardan son falsos o erróneos?
Sin embargo, la solución es más compleja de lo que pueda parecer. Imagina una compañía de seguros que dispone de varias bases de datos con millones de filas en cada una de las bases, y al menos 100 columnas. Invertir tiempo y recursos en comprobar esos datos uno a uno, es imposible de realizar. Para que fuera factible, se requeriría un análisis específico con algoritmos que trataran de solventar los errores más comunes en la recogida de datos. Este algoritmo debería de contar, para ser más eficaz, con un grado de aprendizaje automático o Deep learning.
Gracias a este método se podría reducir bastante la suciedad de los datos, pero nunca se llegaría al margen de error del 0%. Para ayudar a obtener una base de datos lo más veraz posible, debemos trabajar otros aspectos, sin embargo, antes vamos a ver cuáles son las principales causas del Dirty Data, para así comprender mejor sus posibles soluciones.
Principales causas del Dirty Data

Hay un ‘sinfín’ de causas de que aparezcan datos sucios en una base de datos o en una plataforma de Big Data, sin embargo, posiblemente los más comunes sean estos:
- El volumen. Lógicamente, cuanto mayor volumen de datos, más probabilidades de que haya erróneos. Al aumentar el número de datos con la Era Digital, el número de datos sucios, también se ha visto incrementado en la misma proporción.
- Fallos en el registro de los datos. La introducción de datos es clave. Al ser en muchos casos, realizado de forma manual por alguna persona, es muy posible que alguno de ellos acabe siendo grabado de manera errónea o con alguna errata o alteración. En la grabación de datos masiva, es fundamental disponer de un equipo profesional de Data Entry.
- Existencia de silos de información. Muchas empresas aún no disponen de un único sitio en donde tener almacenada y disponer toda la información de la empresa. Este hecho hace que cuando se intenta unificar la información surjan incoherencias y datos duplicados.
- Falta de información. Los registros con campos vacíos provocan que la información que manejamos sea parcial y por lo tanto provoquen decisiones equivocadas.
- Datos falseados. Suele pasar con la información extraída de Internet. Muchos usuarios prefieren dar datos falsos ante el temor de poder ofrecer información verídica a una empresa, sin saber exactamente para qué los va a acabar utilizando. A continuación, te dejo un gráfico extraído de la empresa Verve, donde te muestra precisamente esto.
Tras leer esto, seguro que piensas que puede que dispongas de dirty data en tu base de datos, ¿verdad? Pues si es así, voy a contarte qué puede suponer esto a tu empresa.
Cómo afecta el Dirty Data a una empresa

Por lo general, las empresas que más se verán afectadas por el Dirty Data, son las que ya están utilizando el Big Data. En esos casos, lo normal es que les incurra en:
- Una pérdida de tiempo y recursos. Si dispones de demasiada información sucia en tu CRM por poner un ejemplo, a la hora de sacar conclusiones, segmentar a tus clientes o hacer previsiones, estas serán realizadas de manera más inexacta, repercutiendo en una visión errónea del cliente y una relación con ellos defectuosa. Este hecho repercutirá en que se tendrá que dedicar tiempo extra a ajustar esos mismos estudios, ya que habremos comprobado a posteriori que son falsos, dedicando a su vez, más recursos.
- Una pérdida de ingresos netos. Si tienes pensado realizar una campaña de venta a través de tu Contact Center, disponer de unos datos falseados, erróneos o incompletos en tu base de datos, hará perder claramente clientes potenciales. Según un informe de la empresa Experian, el 77% de las empresas consideran que pierden cerca de un 12% de sus ingresos netos, por falta de datos de sus clientes.
- Decisiones carentes de información. Uno de los mayores avances que han surgido entorno a Internet, la tecnología y los datos, es el poder realizar tomas de decisiones apoyadas en datos, o lo que se llama Data Driven. El Dirty Data puede influir de manera negativa en esa toma de decisiones, ya que estas serían desacertadas.
Y todo esto es debido a datos incompletos, duplicados, incorrectos, imprecisos, inconsistentes o incluso que incumplen las reglas de tu negocio.
Pero ¿cómo podemos solucionar este enorme problema? Vamos a ver ahora qué soluciones podemos poner en marcha para que este Dirty Data nos haga el menor daño posible.
Cómo solucionar el problema del Dirty Data

Siempre la mejor solución para cualquier problema es la prevención, sin embargo, ante este problema, la prevención es realmente complicada, debido fundamentalmente a la gran cantidad de datos o al Big Data. Este hecho, hace imposible crear un sistema fiable.
Una cierta solución, que no llega a ser de prevención, pero se le acerca bastante, es la atención a la calidad del dato. Gracias a ella, evitamos que se produzcan errores al introducir el dato en base de datos. Herramientas de Inteligencia artificial (IA) están comenzando a funcionar muy bien en estos sentidos, validando el dato en tiempo real y ayudando a la calidad de ese dato.
Sin embargo, hay un sistema que se impone sobre los otros dos: el método correctivo, a través del Data Cleaning.
Sin embargo, el sistema del Data Cleaning tiene algunas desventajas:
- Son sistemas costosos.
- Requiere mucho trabajo.
- No se puede automatizar al 100%, ya que muchas veces se necesita de un equipo mixto para realizarlos (técnico y de negocio).
No obstante, lamento decirte que este es el único método para reducir al máximo el Dirty Data dentro de tu plataforma.
Vamos a ver cómo realizar un Data Cleaning exitoso a través de unas sencillas fases:
FASE #1. Detección. Lo primero que debes hacer, lógicamente, es detectar el Dirty Data, ya que no podemos limpiar, si no sabemos qué limpiar. Hay soluciones de Data Profiling que revelan campos vacíos o inconsistencias en los datos. También hay metodologías para asegurar la calidad del dato.
FASE #2. Corrección de los datos. Una vez detectados los errores, hay que subsanarlos, pero no todos son igual de fáciles de arreglar. Por ejemplo, una errata es fácil de solucionar, sin embargo, un dato falso ¿cómo lo corriges por el verdadero? En cuanto a campos vacíos, se pueden rellenar con el dato más probable, haciendo una media, si es dato es numérico, sin embargo, si se hace esto corremos es riesgo que influya en el posterior análisis.
FASE #3. Eliminación de duplicados. En estos casos nos podemos encontrar con que la información que le pudiera faltar a uno de los duplicados, está en la otra. Por tanto, es recomendable, antes de eliminar uno de ellos, juntar todos los datos en uno, y eliminar el duplicado, completando todo lo que fuera posible el uno con el otro.
Como has podido ver, muchas veces nos centramos en el almacenamiento, la gestión de los datos, incluso en métodos y metodologías para sacar conclusiones y conocimiento de los datos, lo cual es fundamental, pero nos olvidamos de la materia prima: el dato. Y es que, si el dato es malo, las conclusiones que saquemos de ellos, y por tanto las decisiones, serán malas. Tal y como se dice en el mundo de los datos “Garbage in, Garbage out”.
En artyco llevamos más de 25 años trabajando con los datos, sacando verdadero oro de cada uno de ellos. Te proponemos algo: “Gold in, Gold out” ¿te apuntas?







Emilio Fernández Lastra
“Después de la hipoteca, el inbound marketing es la mejor
herramienta para asegurar una relación a largo plazo”
¿Te ha parecido interesante lo que has leído?
En artyco podemos ayudarte a conseguir tus objetivos
¿Hablamos?





© Artyco comunicación y servicios - Todos los derechos reservados
© Artyco comunicación y servicios - Todos los derechos reservados

