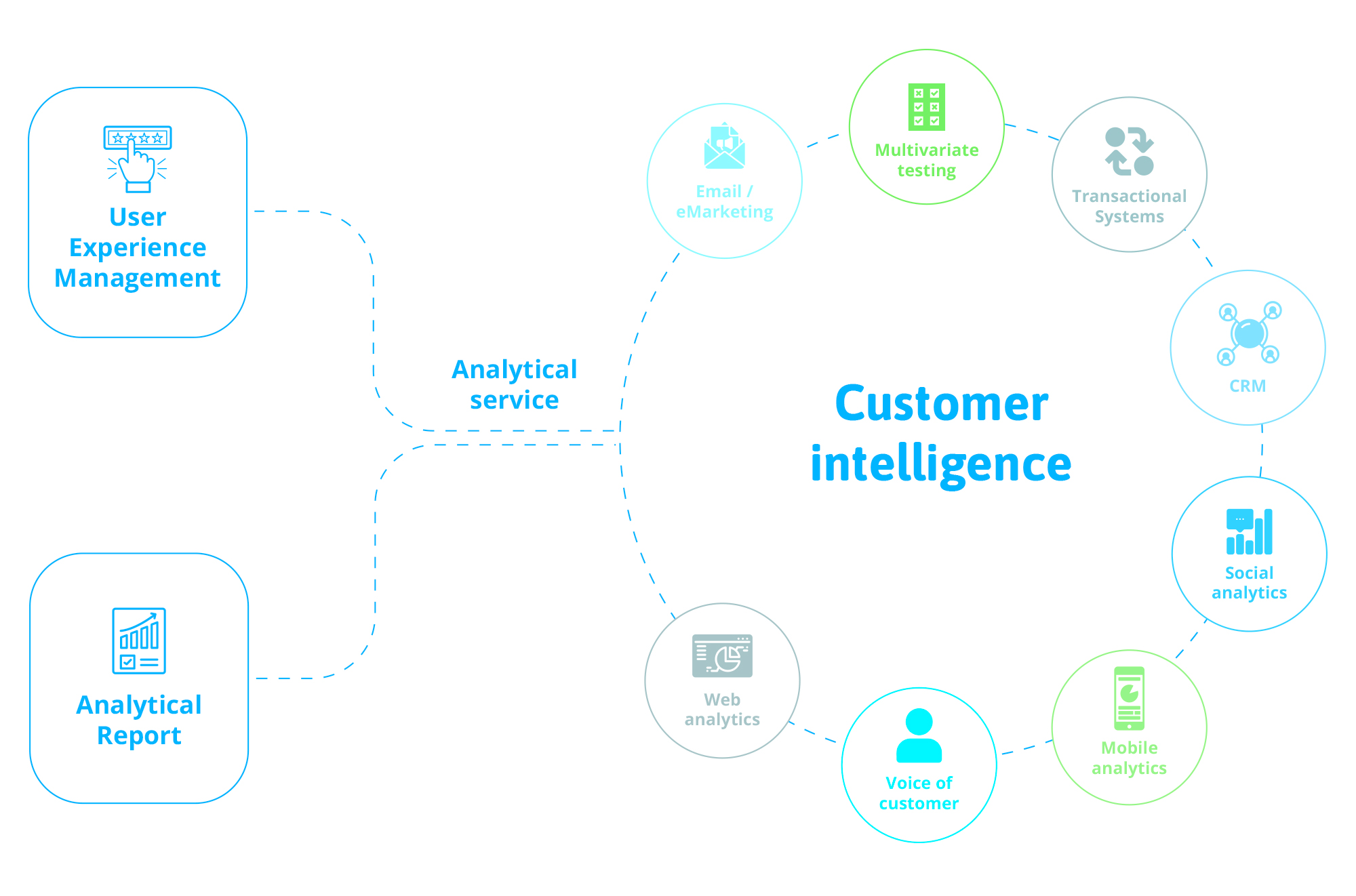
Customer Intelligence
Customer
Intelligence
La mayoría de las empresas han logrado grandes avances en la mejora de la experiencia del cliente (CX) en determinados puntos de contacto digitales. Ahora, el reto está en escalarlo a todos los ámbitos de la empresa. Y para ello, las organizaciones deben obsesionarse con el cliente y poner los datos en el centro de todo lo que hacen para anticipar mejor las necesidades y brindar experiencias personalizadas cuándo, dónde y cómo los clientes lo deseen.
La manera de conseguir esto, es a través del Customer Intelligence, que te permitirá añadir esa capa de inteligencia a tu negocio, logrando relaciones más fuertes y duraderas con tus clientes.
Gracias al Customer Intelligence podrás:
Conocer mejor a tus clientes, qué necesidades tienen, qué les motiva y cuáles son sus intereses.
Posibilidad de una hiperpersonalización en el mensaje que se transmita al consumidor final.
Mejorar la experiencia de cliente, al ofrecerle en el justo momento, aquello que demanda y de la manera que lo precisa.
Tener más fácil el acceso a la información, así como poder intercambiarla con otros departamentos interesados de la compañía.
Planificar la venta cruzada y dirigida, así como detectar clientes potenciales con perfiles similares a los de la empresa.
Encontrar errores o fallos en cuanto al cliente.
¿Quieres centrar tus esfuerzos en el cliente de forma inteligente y con conocimiento?
Déjanos tus datos y un consultor especializado en customer intelligence se pondrá en contacto contigo.
Qué soluciones te ofrecemos
en Customer Intelligence
Identificación de oportunidades off y online.
A través del análisis de la base de datos del CRM de los clientes, logramos identificar oportunidades, tanto en lo online como en el plano físico.

Análisis del ciclo de vida del cliente.
Aquí, te ayudamos a conocer el proceso que sigue el consumidor desde el momento que captas su atención por primera vez, considera tu producto, lo compra, lo utiliza y mantiene la lealtad a tu marca.

Gestión del contenido de comunicación con el cliente.
Identificamos qué tipo de contenidos interesan más a tus clientes, gestionando estos con el objetivo de construir una relación más profunda y efectiva con tus clientes. A través de los canales de comunicación adecuados, en el momento más oportuno.

Análisis de la fidelidad de los clientes.
Para ello utilizamos fundamentalmente los tres principales índices que son: NPS (Net Promoter Score) o grado de lealtad de los clientes; Cuota de cartera; y Churn Rate o tasa de cancelación. Estas métricas te ayudan a tener un mayor conocimiento del estado de tus clientes, de cara a poder tomar decisiones estratégicas al respecto.
Identificación de oportunidades off y online.
A través del análisis de la base de datos del CRM de los clientes, logramos identificar oportunidades, tanto en lo online como en el plano físico.
Análisis del ciclo de vida del cliente.
Aquí, te ayudamos a conocer el proceso que sigue el consumidor desde el momento que captas su atención por primera vez, considera tu producto, lo compra, lo utiliza y mantiene la lealtad a tu marca.
Gestión del contenido de comunicación con el cliente.
Identificamos qué tipo de contenidos interesan más a tus clientes, gestionando estos con el objetivo de construir una relación más profunda y efectiva con tus clientes. A través de los canales de comunicación adecuados, en el momento más oportuno.
Análisis de la fidelidad de los clientes.
Para ello utilizamos fundamentalmente los tres principales índices que son: NPS (Net Promoter Score) o grado de lealtad de los clientes; Cuota de cartera; y Churn Rate o tasa de cancelación. Estas métricas te ayudan a tener un mayor conocimiento del estado de tus clientes, de cara a poder tomar decisiones estratégicas al respecto.
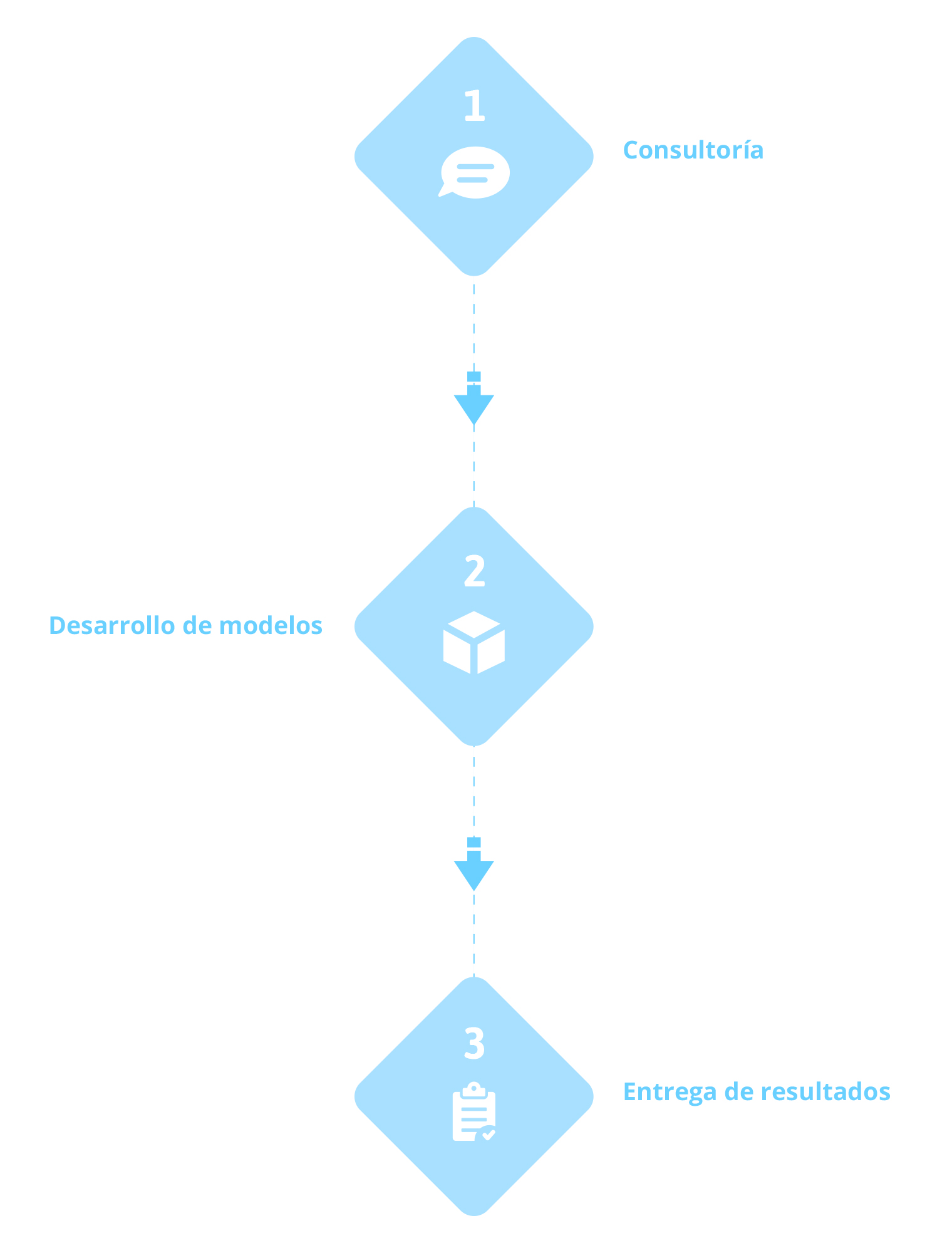
Cómo trabajamos
el Customer Intelligence
En artyco ofrecemos un servicio de consultoría basado en modelos matemáticos que explican o predicen los comportamientos de los consumidores. Estos modelos aprenden de las acciones de los clientes y usuarios, y pueden incorporar tanto el análisis de lo que dicen como la influencia que puedan tener en su círculo social.
Artyco integra, tanto información sociodemográfica y psicológica del cliente, como datos que se obtienen de su actividad, ya sean individuales o sociales, así como datos provenientes de fuentes externas (redes sociales, indicadores económicos o climatología).
A partir de todos estos datos, se generan nuevas variables y modelos matemáticos que explican y predicen los comportamientos de interés. Los resultados permiten, por ejemplo, obtener un perfil más completo del cliente, descubrir segmentos ocultos en función de sus relaciones sociales o de lo que opinan sobre el producto, o predecir el ciclo de vida del cliente.
En artyco ofrecemos un servicio de consultoría basado en modelos matemáticos que explican o predicen los comportamientos de los consumidores. Estos modelos aprenden de las acciones de los clientes y usuarios, y pueden incorporar tanto el análisis de lo que dicen como la influencia que puedan tener en su círculo social.
Artyco integra, tanto información sociodemográfica y psicológica del cliente, como datos que se obtienen de su actividad, ya sean individuales o sociales, así como datos provenientes de fuentes externas (redes sociales, indicadores económicos o climatología).
A partir de todos estos datos, se generan nuevas variables y modelos matemáticos que explican y predicen los comportamientos de interés. Los resultados permiten, por ejemplo, obtener un perfil más completo del cliente, descubrir segmentos ocultos en función de sus relaciones sociales o de lo que opinan sobre el producto, o predecir el ciclo de vida del cliente.
Trabajamos con las mejores herramientas y partners










© Artyco comunicación y servicios - Todos los derechos reservados
© Artyco comunicación y servicios - Todos los derechos reservados